SGLang 0.4.4 企业级推理加速框架
SGLang 是一个专为高效部署大型语言模型(LLMs)和视觉语言模型(VLMs)设计的开源框架,其核心优势在于优化的后端运行时和灵活的前端交互能力,支持多种性能优化技术(如张量并行、数据并行、量化等),在推理速度和资源利用率上表现优于传统工具(如vLLM)。
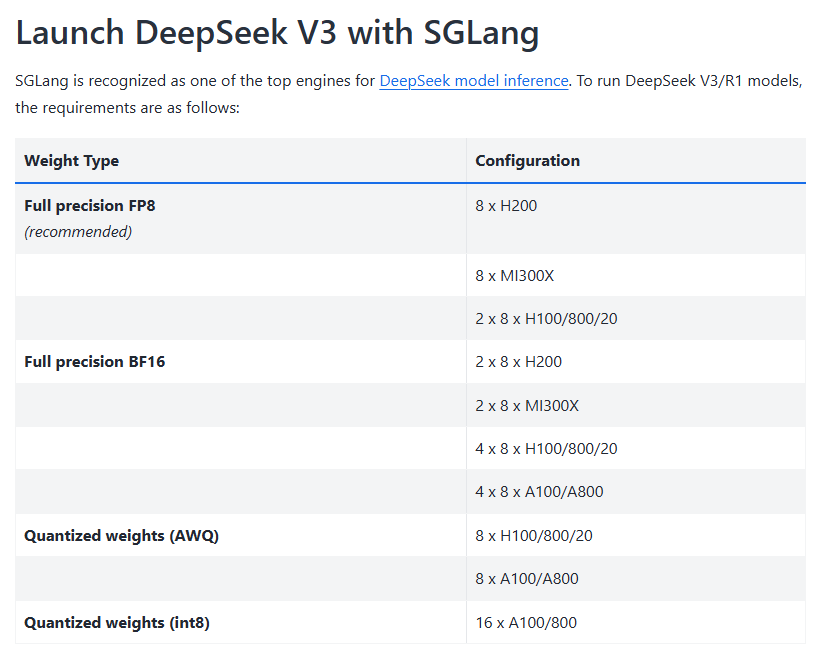
官方建议跑满血版本 Deepseek V3 的硬件要求。
开源项目地址:https://github.com/sgl-project/sglang
核心特性
高性能后端
多模态与模型兼容性
灵活的前端接口
环境要求
Python 3.8+(推荐 Python 3.12,与 SGLang 兼容性最佳)
CUDA 11.8 或更高版本(若使用 NVIDIA GPU)
安装方法
1.创建虚拟环境
conda create -n sglang python=3.12
conda activate sglang
2.安装 SGLang 0.4.3 及核心依赖
pip install sglang==0.4.3 vllm sgl_kernel
3.处理FlashInfer依赖
FlashInfer 是 SGLang 的优化组件,需手动安装预编译包:
访问 FlashInfer 官网,根据 CUDA 版本下载对应的 .whl 文件(如 flashinfer-0.2.0.post1+cu124torch2.4-cp312-cp312-linux_x86_64.whl)。
安装时避免自动安装冲突的 PyTorch 版本:
pip install flashinfer-*.whl --no-deps
4.验证安装
python -c "import sglang; print(sglang.__version__)"
# 输出应为:0.4.3
5.启动 SGLang 服务
# 启动服务并加载模型(示例使用 Llama-3-70B)
python -m sglang.launch_server \
--model-path meta-llama/Meta-Llama-3-70B-Instruct \
--port 8123 \
--tp 4 # 根据 GPU 数量调整张量并行数
本文采用署名-非商业性使用-相同方式共享 4.0 国际许可协议[CC BY-NC-SA]进行授权 | 作者:CodeF
文章固定链接:https://www.codef.cc/sglang-inference-acceleration-framework.html
本站资源仅供个人学习交流,请于下载后 24 小时内删除,不允许用于商业用途,否则法律问题自行承担。
本站软件默认解压密码均为:CodeF.cc
文章固定链接:https://www.codef.cc/sglang-inference-acceleration-framework.html
本站资源仅供个人学习交流,请于下载后 24 小时内删除,不允许用于商业用途,否则法律问题自行承担。
本站软件默认解压密码均为:CodeF.cc
THE END